
Migrating from Couchbase to MongoDB: A Detailed Case Study
This article demonstrates how to take information (documents) from a Couchbase database and migrate them to a MongoDB database using Apache Kafka, creating and testing the functionality of Insert, Update and Delete operations.
This approach allows for a gradual migration, mirroring the data between Couchbase and MongoDB and keeping it up to date on both. Applications may then be switched from one data source to the other at a comfortable pace, minimising business, and technical risk.
Generally, we recommend this more cautious approach versus a “big bang” all-at-once migration as it enables addressing application updates on a gradual timescale in line with agile development.
Why MongoDB?
MongoDB has proven popular with many of our customers and offers both cost reduction and increased technical flexibility versus other NoSQL database offerings, offering a large partner ecosystem and double the language support that Couchbase currently offers.
As one of the most desirable databases to learn and work with (per Stack Overflow’s 2022 Developer Survey), there’s also the security of an established and growing population of specialists in MongoDB.
You can read more about MongoDB (and how it compares with Couchbase) in MongoDB’s own article.
High-Level Overview
We begin with a high-level overview of databases and the platform we have set up.
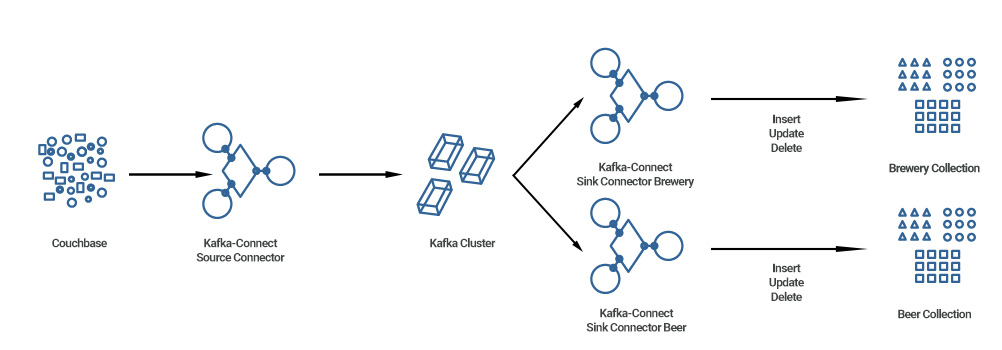
- A Couchbase instance.
- A Kafka cluster.
We will create a Kafka source connector that will fetch data from Couchbase and push it to the Kafka cluster.
- A MongoDB instance.
We will create two sink connectors that will push data to MongoDB and also allow Insert, Update and Delete operations.
Starting with Couchbase
Within our Couchbase we have a bucket called “beer-sample” with 7,303 items (or elements) in it.

Going into the documents within the beer-sample bucket, you can see that each document has a “type” field with a value of either “brewery” or “beer”.
We would like to collect those documents and push them to MongoDB where they’ll be placed in two collections also called “brewery” or “beer”.
Next, in Kafka
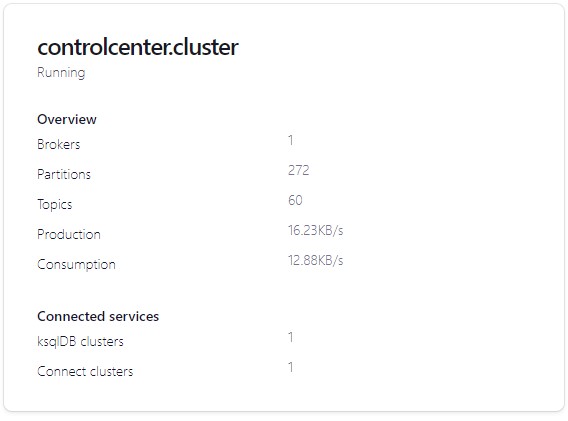
Meanwhile, in Kafka, you can see that we have one cluster:
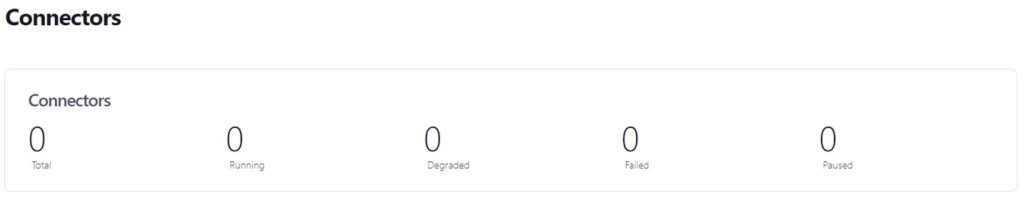
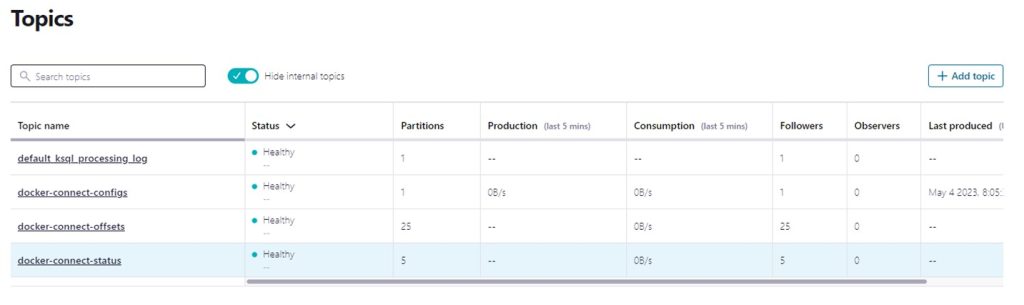
You can also see that we only have the default Docker Topics and in Kafka Connect, we don’t have any connectors:
First, we install three additional plugins:
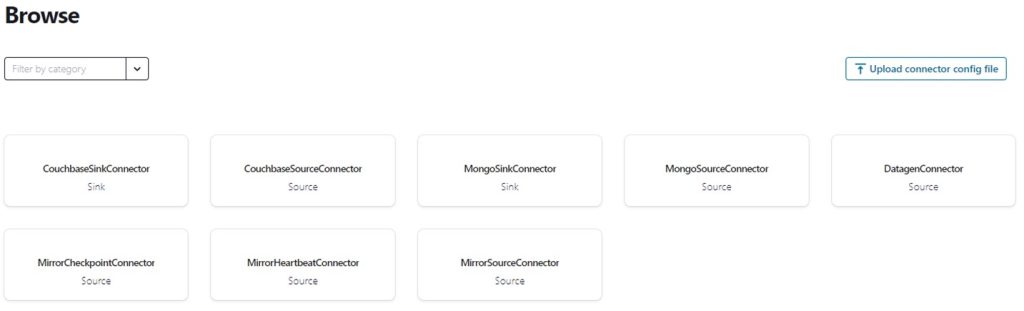
- Kafka-connect-MongoDB which allows Kafka to connect with MongoDB.
- Kafka-connect-Couchbase which allows Kafka to connect with Couchbase.
- Connect-transforms which is used to assign data into the correct collections.
Next, we create a source connector for Kafka that will fetch the data from Couchbase:
Several areas have been specified within this:
- “name”
- “couchbase.topic” which specifies where we would like to push the data e.g. “beer-sample-topic” within Kafka.
- “couchbase.bucket” used to specify the bucket from which to get the data.
- “couchbase.username” and “couchbase.password” which allow Kafka to access this Couchbase database.
With this source connector created, we can go back into Connectors in Kafka where we can see that running as “couchbase-beer-sample-source”:
![]()
We can then check Topics where we see the new “beer-sample” topic created and running.

Clicking into the Messages of that Topic, you can see the max offset number is 7302 elements. In Couchbase we have 7303 elements. The difference exists because Kafka indexes from zero – so this is correct.

Pushing data to MongoDB
Leaving Kafka for a moment, we open and connect to MongoDB.
Inside, we have a Couchbase migration database with one collection titled: ”couchbase_migration_poc” that is empty.
The next step is to create our two sink connectors for MongoDB which will be called “mongo_beer_sink” and “mongo_brewery_sink”. Below you can see the first of these:
Looking through the functionality of this connector we have:
- “topics” which in this case will be “beer-sample-topic”, specifying which topic we will read messages from.
- “connection.uri” which specifies what the connection will be.
- “database” which in this case will be “couchbase_migration_poc”
- “collection” which specifies which collection to push the data to within the above database – in this case, collection “beer”.
- The “transforms” lines which specify we would only like to include messages that have a type value of “beer”. This is what will allow us to push “beer” messages to the “beer” collection and “brewery” messages to the “brewery” collection.
Checking that this works…
Going back to Kafka, within Connect, there should now be three connectors:

- One source connector for Couchbase: “couchbase-beer-sample-source”
- One sink connector for Brewery: “mongo-brewery-sink”
- One sink connector for Beer: “mongo-beer-sink”
Going back to MongoDB, we reload the data and see that there are 2 additional collections: “beer” and “brewery”:
If we count the elements within both, there are 5891 within “beer” and within “brewery” there are 1412, resulting in 7303 elements. Exactly the same as the document count within our bucket in Couchbase.


Having checked our “beer” and “brewery” documents, we can see that our “Inserts” functionality looks good.
Searching, Updating and Deleting
We can further check that the data has transferred correctly by going back into Couchbase and searching for data from one of the elements in MongoDB.
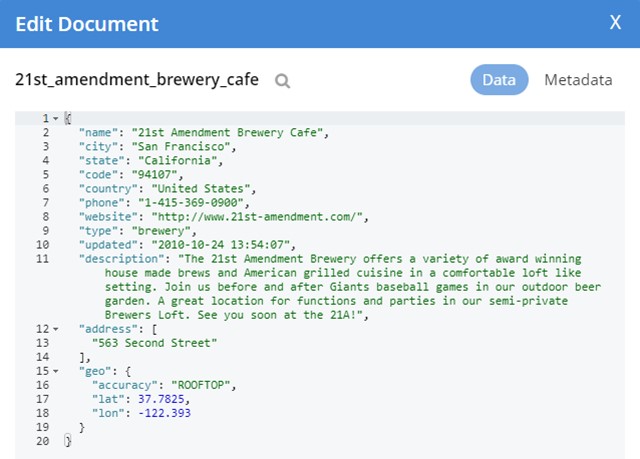
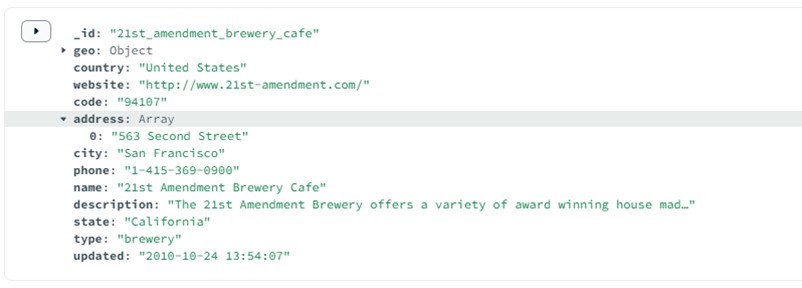
In the same places, we can check that our “Update” functionality works. This is done by updating data in Couchbase (We added another address):
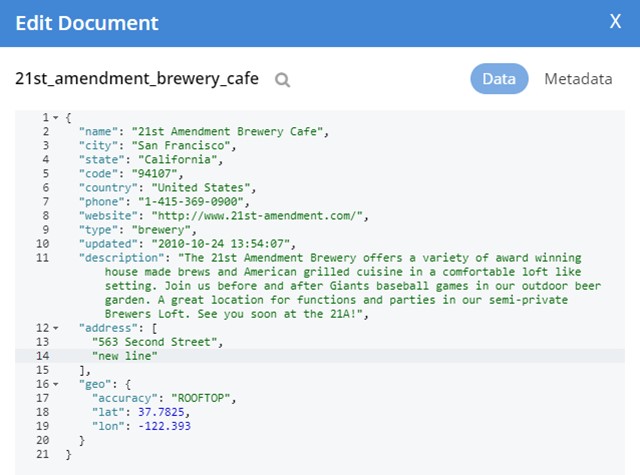
If we save this, go to MongoDB and refresh that data, we find that the changes have updated across:
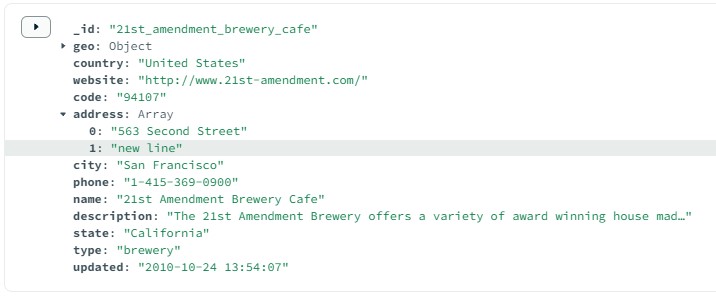
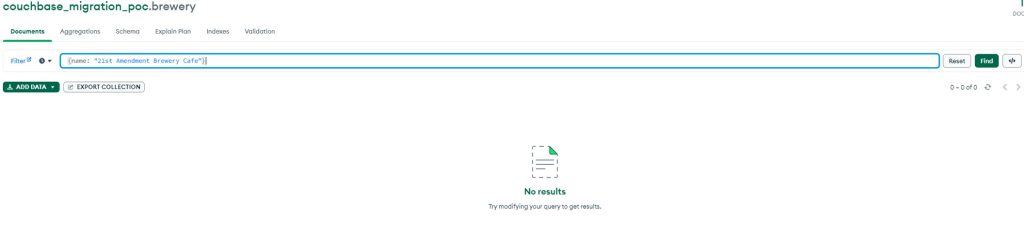
And lastly, we check the deleting documents. In Couchbase we select that document for deletion and confirm this:
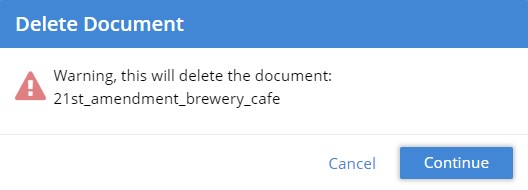
And if go back to MongoDB and hit ‘refresh’, that document is no longer presented as a result.
This confirms that our Insert, Update and Delete functionality works well and we have successfully illustrated how you would migrate data from a Couchbase database to MongoDB using Kafka.
As outlined at the opening of this article, our approach here allows for the synchronisation of data updates across both Couchbase and MongoDB, so that subsequent changes to application data sources may be gradual and controlled, thus limiting risk to the business and for the migration to proceed at a controlled and comfortable pace.
If you’d like to discuss this article, our process or what we can do, drop us a line!