
gravity9 System Architecture Guide: Lambda Architecture
02 Sep 2024 | Przemysław Serwicki
Architecture is a vital aspect of all systems and applications, serving as a blueprint for engineers that defines behavior and structure. There are numerous architectural patterns out there and they can be used on different levels of a system – a single system can use multiple architectural patterns!
As a digital consultancy, gravity9 has a rich history and heritage of development, picking the best architecture for the job.
In this series of articles, we’ll introduce some of the most popular system architecture around. We’ll look at why they’re popular, where they’re useful, and where they’re less useful.
The Challenge of Analyzing Real-Time Data Quickly
Monolithic architecture can struggle to analyze real-time data alongside large-scale historical data, as there’s often only a single data pipeline to handle both. Growing volumes of data moving through such a system can result in unwanted processing delays and outdated data insights.
For organizations that require real-time insights from continuous streams of data, such as an e-commerce platform that offers personalized recommendations to customers based on their browsing and purchasing histories, issues with data processing (in this case, resulting in inaccurate recommendations) could be devastating.
So, what can be done to ensure that systems support the needs of organizations that require high-performance processing of both real-time and large-scale data?
Introducing Lambda Architecture!
Lambda Architecture is an architectural paradigm designed to enable real-time and large-scale data processing simultaneously by separating real-time and batch-processing layers.
In fact, it is built on three core layers:
The batch layer is responsible for ingesting and storing large volumes of data from various sources. It plays an important role in preparing this data for indexing by managing a master dataset. The master dataset is treated as immutable and append-only, providing a reliable historical record. The batch layer operates at scheduled intervals, often overnight, processing large datasets with fault tolerance and scalability in mind. Its primary functions are to manage the master dataset and precompute batch views, providing a comprehensive foundation for further analysis and reporting.
Referring back to our e-commerce platform example, the batch layer would process vast amounts of historical customer data, such as past purchases and browsing behavior, to generate comprehensive insights for future analysis.
The speed layer (also known as the stream layer) specializes in collecting and processing real-time data. It complements the serving layer by indexing the most recently added data (that hasn’t yet been fully processed by the batch layer), effectively narrowing the gap between data creation and its availability for querying. By leveraging stream processing software such as Apache Flink or Apache Spark Streaming, the speed layer ensures low-latency processing of high-velocity data streams. This layer is crucial for filling the gaps left by the batch layer, ensuring the most up-to-date information is available for decision-making.
In our e-commerce platform example, the speed layer would process real-time customer actions, such as clicks and searches, to provide immediate personalized recommendations.
The serving layer acts as the bridge between the batch and speed layers. It incrementally indexes the latest batch views while also integrating real-time updates from the speed layer, ensuring a unified and consistent dataset for user queries. This layer is designed for fault-tolerant and scalable processing, enabling rapid responses to high volumes of requests. By exposing service endpoints, it allows external components and applications to seamlessly access and query the merged data, efficiently creating a queryable dataset from the outputs of both the batch and speed layers.
In our e-commerce platform example, the serving layer would combine historical purchase data with real-time browsing behavior to deliver accurate, up-to-date, personalized recommendations.
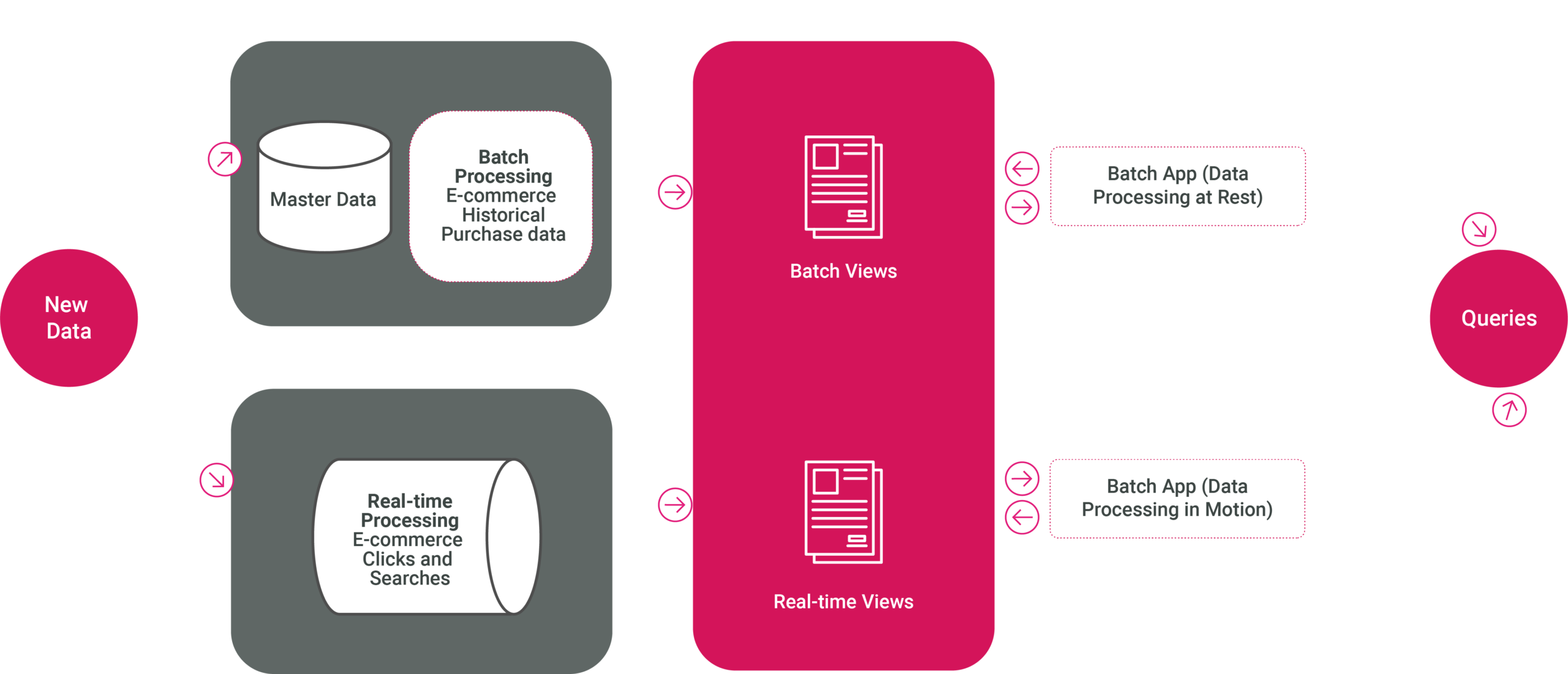
In some cases, though not a typical form of Lambda Architecture, the serving layer can be enhanced to provide even lower latency or access to precomputed views generated by the batch and speed layers. This can be useful where immediate access to fresh data is critical.
In our e-commerce platform example, an enhanced serving layer might store precomputed recommendation datasets and real-time data in an optimized format, ensuring that the response is instantaneous when a customer searches for an item or views a product page. This also reduces the need for on-the-fly processing, enhancing the speed and reliability of user interactions.
Lambda Architecture Advantages (And Where To Use It)
As we’ve established, Lambda Architecture excels in situations where rapid processing of real-time and large-scale data is important to your requirements.
-
Serverless Management (Speed Layer): Lambda Architecture typically simplifies system management via a serverless approach to the speed layer, eliminating the need to install, update, or maintain server software.
-
Fault Tolerance: By leveraging the strengths of distributed systems, Lambda Architecture can ensure continuous data processing even in the event of system errors or failures. Data is stored in the batch layer, providing a robust route to recovery in the event of any failure.
-
Scalability: A further benefit of Lambda Architecture employing distributed systems and cloud storage is its inherent scalability, which dynamically evolves to meet business demands regardless of data volume.
-
Real-Time Data Access: Traditional batch processing struggles with streaming data, particularly transactional data. Lambda Architecture overcomes this limitation by integrating a fast streaming data pipeline alongside a dedicated serving layer. This setup allows the architecture to query data as it is generated, enabling real-time processing and allowing users to receive immediate results!
When data flows continuously into a system, and it’s crucial to analyze real-time and historical data to make informed decisions, Lambda Architecture is a great solution:
-
Big Data Applications: Lambda Architecture excels by effectively managing vast volumes, varying velocities, and diverse data types. Industries such as e-commerce, banking, and credit card transactions benefit significantly from its flexibility and scalability.
-
Internet of Things (IoT): When real-time data is generated by a multitude of devices and sensors in an IoT ecosystem, Lambda Architecture is highly effective in handling both batch processing and real-time data streaming.
-
Machine Learning: Machine learning models often require continuous training on up-to-date data to maintain accuracy and relevance. Lambda Architecture’s speed layer allows for the integration of real-time updates into the model training process, ensuring that models are always working with the latest data. Meanwhile, the batch layer provides the necessary historical context, leading to more comprehensive and effective model training.
Lambda Architecture Disadvantages
As powerful as Lambda Architecture is, there are certain aspects to consider before thinking it is the perfect solution in all cases!
-
Additional Complexity: Lambda Architecture introduces significant complexity by requiring the maintenance of multiple components and two separate codebases (for the batch layer and the speed layer), which must be synchronized in order to achieve consistent results.
-
Cost: Lambda Architecture includes numerous components running on different software, which incurs a material cost and requires specialized skills to manage and maintain the architecture. For organizations with limited resources, this can be a significant drawback in implementing Lambda Architecture.
-
Data Redundancy and Overhead: Lambda Architecture can lead to data duplication between the batch layer and the speed layer. This redundancy risks data inconsistency and wasted storage space. As data accumulates, the architecture may require extensive additional effort to reorganize or migrate datasets, further increasing the complexity and cost.
Lambda Architecture is most useful in situations where real-time and historical data processing are important. However, in situations where this isn’t a factor, other approaches may be a wiser choice and result in lower system complexity, reduced costs, and fewer organizational overheads to maintain it.
What Are The Best Tools For Implementing Lambda Architecture?
Let’s refer again to our example: an e-commerce platform that wants to process large volumes of transactional and behavioral (customer) data in real-time in a way that is fault-tolerant and scalable to business growth.
Processing this data allows the platform to provide personalized recommendations and dynamic pricing to customers while analyzing usage trends, customer behavior, and conducting inventory management.
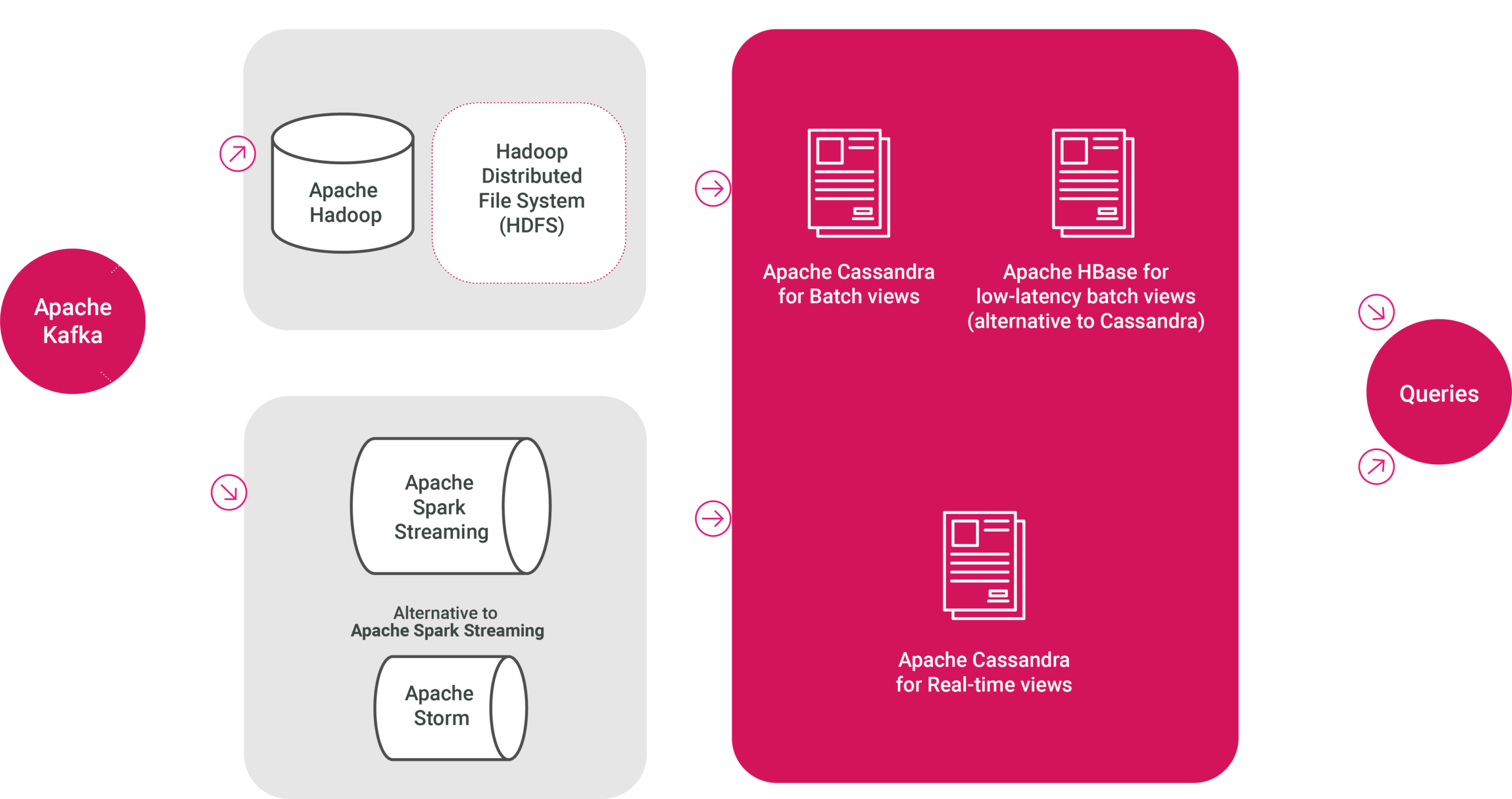
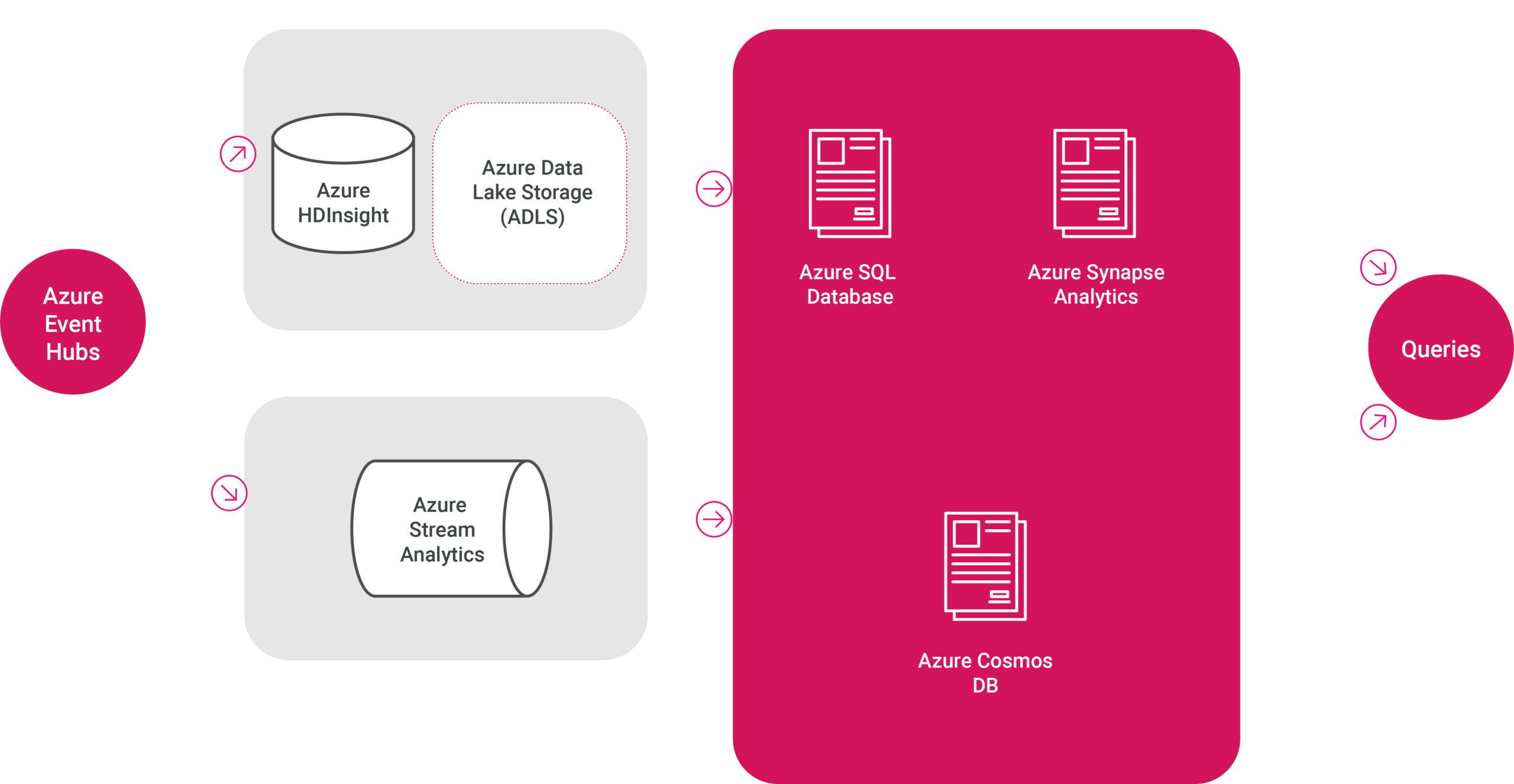
Here’s a break-down of two leading product ranges (Apache and Microsoft Azure) that could be used to implement Lambda Architecture, which we’ve already established as an excellent solution for this type of use case:
Component and Associated Layer: Batch Processing (Batch Layer)
Product: Apache Hadoop (or) Microsoft Azure HDInsight / Synapse Analytics
Role: Distributed storage and processing of large datasets. Handles batch processing of historical data, enabling in-depth analysis and reporting.
Component and Associated Layer: Data Storage (Batch Layer)
Product: Hadoop Distributed File System (HDFS) (or) Azure Data Lake Storage (ADLS)
Role: Primary storage system that stores raw, immutable data efficiently across a distributed environment, ensuring high availability and scalability.
Component and Associated Layer: Data Orchestration (Batch Layer)
Product: Apache Oozie (or) Azure Data Factory
Role: Orchestrates and automates complex data workflows, ensuring that data is processed in the correct sequence and distributed to the appropriate layers.
Component and Associated Layer: Data Streaming (Ingesting into Batch and Speed Layers)
Product: Apache Kafka (or) Azure Event Hubs
Role: Real-time data streaming platform that ingests, buffers, and processes large volumes of data in real-time, providing a continuous flow to batch and speed layers.
Component and Associated Layer: Real-Time Processing (Speed Layer)
Product: Apache Spark Streaming / Storm (or) Azure Stream Analytics
Role: Processes real-time data streams with low latency, allowing for immediate data insights and action. Ideal for scenarios where up-to-the-second data processing is critical.
Component and Associated Layer: Serving / Views Storage (Serving Layer)
Product: Apache Cassandra (or) Azure Cosmos DB
Role: Stores real-time views with high write throughput and low latency, ensuring data is readily available for fast, real-time querying and decision-making.
Component and Associated Layer: Batch Views Storage (Serving Layer)
Product: Apache HBase (or) Azure SQL Database / Azure Synapse Analytics
Role: Stores precomputed views of historical data optimized for quick access to large datasets. Essential for generating reports and supporting complex queries efficiently.
A solution based on Apache products can be seen in the image below:
A solution based on Microsoft Azure products can be seen in the image below:
Is Lambda Architecture Right For YOU?
Lambda Architecture is a robust solution for data processing, offering a well-balanced approach to managing latency, throughput, and fault tolerance. It’s an excellent and scaleable choice for organizations that need to process real-time data quickly while still analyzing large amounts of historical data without performance loss.
However, Lambda Architecture can be costly and complex and brings challenges associated with data duplication. These should all be considered before thinking it a perfect solution in all situations, as in some, it may simply be overkill!