
Enhancing Autism Care with AI Agent Solution
04 Mar 2025 | Loghman Zadeh
Enhancing Autism Care with AI agent solution based on LlamaIndex and MongoDB
Introduction
Imagine a system where clinicians effortlessly access and interpret complex patient data through simple, natural language queries. This vision became a reality through an agentic AI solution developed by gravity9. By leveraging the LlamaIndex and MongoDB platforms, gravity9 created sophisticated question-answering workflows that significantly enhance data retrieval and user interaction for our client working in the field of Autism and IDD care.
1. Project Background
CentralReach is a healthcare technology company providing an end-to-end Applied Behavior Analysis (ABA) services platform. Their mission is to scale ABA services efficiently, enhancing care for individuals with autism and intellectual and developmental disabilities (IDD). The company offers a comprehensive suite of clinical, operational, and financial management tools within therapy and healthcare settings. CentralReach integrates various services and technologies to improve clinical outcomes and streamline operational processes, helping organizations provide more effective care.

Central Reach faced significant challenges managing complex, unstructured patient data. A key element of their system is Learning Trees—versatile, hierarchical data structures that store varied information about patients, including demographics, medical history, treatment progress, and associated documents.

2. Key Challenges
Managing such intricate and unstructured data presented several challenges:
- Flexible Data Structures: Learning Trees lacked a strict schema, allowing clinicians to store information with varying levels of detail and in different orders.
- Diverse File Formats: Many nodes referenced external files such as PDFs and Word documents stored in AWS S3 buckets, which contain vital information in text, images, diagrams, and tables.
- Data Retrieval Inefficiencies: The unstructured format made it challenging to quickly retrieve specific information and analyze data for valuable insights.
- Interactive Querying Needs: Clinicians needed an intuitive system for interacting with data using natural language queries, which would provide accurate and detailed responses based on patient information.
4. Proposed Solution Based on LlamaIndex
To address the challenges of managing unstructured Learning Tree data and enabling seamless, AI-powered querying, we built the solution using LlamaIndex as the core platform. LlamaIndex served as the foundation for integrating Large Language Models (LLMs) with enterprise data, providing the necessary tools for efficient data ingestion, enrichment, retrieval, and reasoning.
LlamaParse for content extraction
As part of the project architecture, LlamaIndex contributed by implementing the content extraction solution for files stored in AWS S3 buckets. This integration played a crucial role in handling diverse file formats (PDF, Word, images) and extracting relevant content such as text, tables, images, and diagrams, which was essential for enriching the Learning Tree data.
LlamaIndex is a framework for building applications that use LLMs. It’s used to integrate private data with public data to create generative AI (gen AI) applications. LlamaIndex focuses on simplifying the process of connecting and managing data for Retrieval-Augmented Generation (RAG), Agentic AI, and other AI-driven solutions.
LlamaIndex offers a suite of tools and technologies designed to enhance data processing, retrieval, and AI integration:
- LlamaCloud:A secure and scalable cloud-based platform that serves as a knowledge management layer, making unstructured data LLM-ready. LlamaCloud facilitates the production of knowledge assistants by providing an intuitive interface for configuring retrieval-augmented generation (RAG) pipelines and handling multi-modal data embedded within documents during both ingestion and retrieval.
- LlamaParse: A document parsing service that transforms complex documents—including those with tables, charts, images, and flow diagrams—into formats optimized for LLM applications. LlamaParse allows to securely parse complex documents such as PDFs, PowerPoints, Word documents and spreadsheets into structured data using state-of-the-art AI.
- LlamaIndex Framework: A flexible framework for building agentic generative AI applications, allowing LLMs to interact with data in any format. This framework supports the development of AI agents capable of complex reasoning, task planning, and API interactions, enhancing the capabilities of LLM-powered applications.
- Data Connectors: LlamaIndex provides connectors for various data sources, allowing seamless integration with databases, cloud storage, and APIs, enabling unified access to structured and unstructured data.
LlamaIndex was selected for several compelling reasons:
- Advanced Content Extraction: LlamaParse demonstrated exceptional accuracy in extracting meaningful information from complex documents, including those with non-standard layouts and embedded multimedia elements.
- Scalability and Security: LlamaCloud’s SOC 2 compliance and auto-scaling capabilities ensured that our solution could securely handle large volumes of data while maintaining performance.
- Seamless AI Integration: The LlamaIndex Framework provided the flexibility to build AI agents that could effectively interact with our enriched Learning Tree data, facilitating advanced querying and reporting functionalities.
- Rapid Implementation: LlamaIndex’s comprehensive tools and intuitive interfaces allowed for quick deployment, reducing development time and accelerating the delivery of tangible outcomes to the client.
4. Solution Overview
To address the client’s challenges, an AI solution was implemented with two key components:
Data Ingestion and Enrichment Pipeline:
- This microservice processes the Learning Tree data stored in MongoDB, analyses its structure, and enriches it by summarizing and classifying individual nodes.
- Enriched and vectorized tree node data is stored in MongoDB to enable fast and scalable retrieval.

Agentic Workflows:
- An AI-powered question-answering workflow was developed to allow users to interact with the Learning Tree data through natural language queries. The workflow interacts with users to clarify the user query and get details as much as possible to improve the data retrieval and response quality.
- The system translates user queries in natural language into MongoDB queries, utilizing hybrid retrieval methods that combine vector-based semantic search with traditional keyword-based search for optimal results.

5. Solution Architecture
The system architecture for this solution is designed to process, enrich, and enable querying of flexible and unstructured Learning Tree data stored in MongoDB. As mentioned in the previous section, the architecture comprises two main components: Data Ingestion and Enrichment and Agentic Service. These components work together to transform raw data into a searchable knowledge base and provide users with a powerful AI-powered question-answering capability.

Data Ingestion and Enrichment
The Data Ingestion and Enrichment pipeline is implemented as a microservice that encompasses several key processes:
- Taxonomy Processing: The system builds a hierarchical structure of categories using Learning Tree Standard Reference Markdown files. This taxonomy aids in classifying nodes during the enrichment process, ensuring consistent categorization across diverse data entries.

- Learning Tree Analyzer: This component extracts data from the Learning Trees, analyzes the tree structure, and adds hierarchical relationships to nodes as new metadata. The process prepares the data for subsequent enrichment stages, ensuring the integrity and structure of the data are preserved.
- Enrichment Pipeline:
- Node Summarizer: Generates concise summaries for each node using an LLM, capturing essential information and making the data more accessible.
- Node Classifier: Categorizes nodes into predefined taxonomy categories using large language models (LLMs), ensuring each node is accurately labelled for easier retrieval.

-
- File Content Extraction: Leveraging components provided by LlamaIndex , the system extracts content from diverse file formats stored in AWS S3 buckets using LlamaParse, effectively handling text, images, diagrams, and tables
- Vectorization Pipeline: This section converts enriched data into vector embeddings using an embedding model. This process facilitates semantic search and retrieval, enabling the system to understand and process queries more intelligently.
- MongoDB Knowledge Base: Stores the enriched and vectorized data, preparing it for scalable and efficient querying. Future developments include the construction of a knowledge graph to capture relationships between nodes, further enhancing query capabilities.
Agentic Workflows
The Agentic Service provides AI-driven workflows for querying the enriched data stored in the MongoDB Knowledge Base. It includes tools and agents developed based on Llama Agent that allow users to interact effectively with the system.

Key Components of agentic workflows:
- AI Workflow & Agents: Facilitates end-user interactions and reasoning process using following workflows:
- Query refinement workflow: An agent interacts with the user to obtain the query and asks follow-up questions to get the required details to answer the query.
- Reasoning and response generation workflow: Find the relevant nodes related to user query from the enriched learning trees and summarize them and using an LLM to answers user query.
- Citation workflow: Trace the lineage of the data by listing the nodes that the response is based on.
- Tools:
- Expression-based retrieval: This tool converts natural language queries into MongoDB queries, supporting lexical, semantic, and hybrid search types.
- Summarization tool: Generates a textual summary form a tree node data.
- Monitoring and Logging:
- Logs and tracks all agentic interactions using tools like LangFuse, enabling transparency and observability.
Interactive Question Refinement
At the core of our system is the Question Refinement workflow. When clinicians present a query, a LlamaIndex workflow is triggered, initiating an interactive dialogue. This process involves suggesting refinements and rephrasing questions for improved clarity. As a result, inquiries become more specific and utilize domain-specific terminology related to autism care, which leads to more accurate and relevant responses.

The workflow includes a loop in which a LlamaIndex AI agent generates the following in each iteration:
- Suggestions on how the user can make their question more precise
- A rephrased version of the user’s question
- A written record of any domain-specific vocabulary that the user has explained (for future reference)
- An expression that will be used to find relevant data during the querying process

Contextual analysis and reasoning process
Once the user question is refined, the second LlamaIndex workflow will start for the context-gathering and reasoning process. This workflow utilizes information generated by question refining workflow to answer the user query.
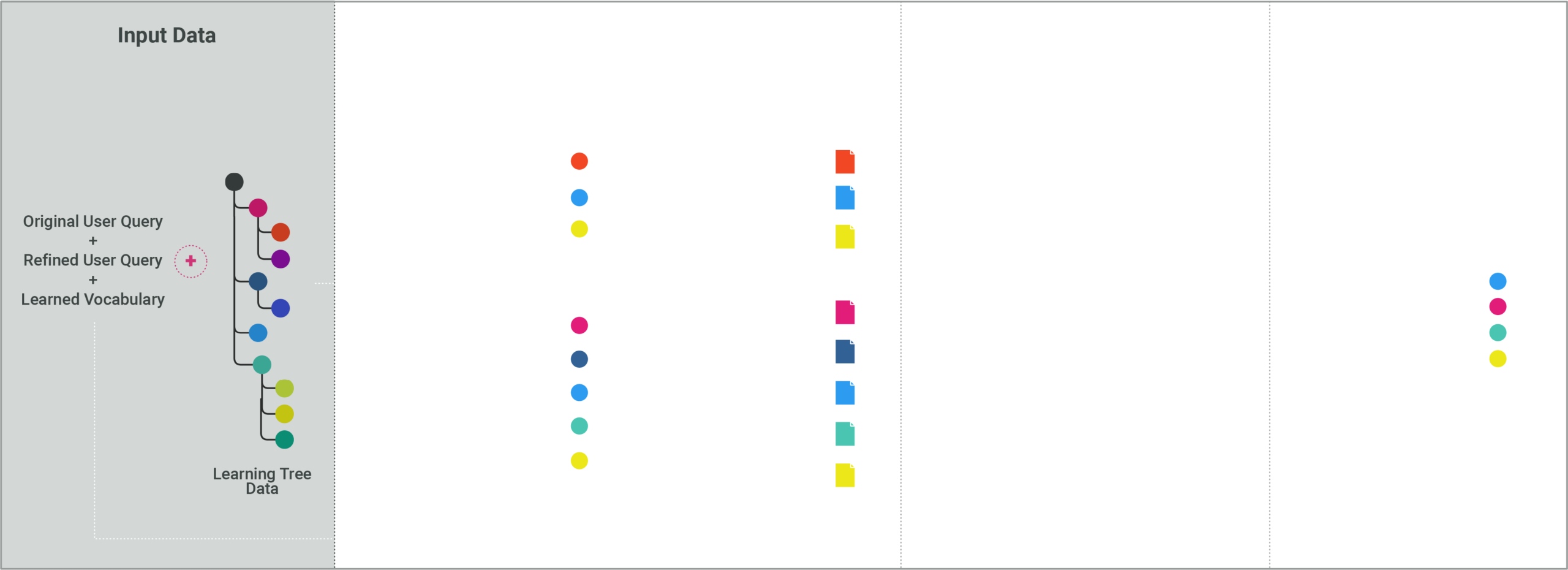
This workflow consists of three steps:
- Context gathering: A context analyzer AI agent examines a simplified schema of the learning tree to determine which nodes are relevant for answering the user’s query. In parallel, an expression-based filtering component translates the user’s query into MongoDB query language and provides three types of filters: lexical, semantic, and hybrid search. These filters are used to retrieve relevant nodes from the learning tree. The outputs from the context analyzer agent and the expression filtering are passed to a data summarizer agent to generate a natural language summary from filtered nodes data. Then, the summary of selected nodes will be passed on to the reasoning process in the next step.
- Reasoning and response generation: After an AI agent receives the original user query along with a refined version, extracted vocabulary, and the provided context from the previous step, it will run the chain of thought process and answer the user’s question.
- Citations generation: An AI agent assesses the connection between specific parts of the answer and the filtered learning tree nodes, then returns the response along with a list of nodes that contributed to constructing the question response.


6. Achievements and Outcomes
The implementation of this agentic AI solution has led to several significant achievements and outcomes:
- Time Savings for Clinicians: Clinicians can now obtain precise answers to their queries without manually sifting through extensive Learning Tree data, allowing them to focus more on patient care.
- Enhanced User Experience: The intuitive interface and efficient data retrieval processes have improved the overall user experience, making the system more accessible and user-friendly.
- Improved Data Retrieval and Analysis: Advanced reasoning capabilities enable clinicians to perform complex tasks, such as calculating specific metrics and identifying root causes of issues, leading to more informed decision-making.
- Refined Query Processing: The system’s query refinement process clarifies user intentions, resulting in more accurate and relevant responses.
- Development of a Comprehensive Vocabulary: Extracted terms during query refinement contribute to building a comprehensive dictionary, serving as a valuable resource for future applications.
- Increased Trust and Confidence: By providing citations and linking responses to original data sources, the system enhances clinicians’ trust in the information, supporting evidence-based practice.
- Scalable and Future-Proof Architecture: The architecture, built upon LlamaIndex, Llama Agents, and workflows, offers scalability and adaptability, ensuring the system remains robust and relevant as future needs evolve.
- Foundation for Knowledge Graph Development: The content extraction process using LlamaParse lays the groundwork for constructing a knowledge graph, which can further enhance data retrieval quality and open avenues for future use cases.
These outcomes collectively contribute to more efficient, accurate, and user-friendly data management and retrieval in clinical settings, ultimately supporting better patient care.
7. Conclusion
The successful implementation of this AI-powered agentic solution marks a significant step forward in enhancing autism and IDD care. By integrating LlamaIndex, LlamaParse, and MongoDB, we developed a robust, scalable architecture that transforms how clinicians interact with complex patient data. The system’s ability to process unstructured Learning Tree data, extract meaningful insights, and provide accurate responses through natural language queries has not only saved time for clinicians but also improved the quality of care they can deliver.
Key achievements, such as refined query processing, advanced reasoning capabilities, and citation-backed responses, have empowered clinicians to make informed decisions with greater confidence. The system’s interactive workflows, coupled with seamless content extraction and enriched data retrieval, have provided a superior user experience while laying the foundation for future innovations, including the development of knowledge graphs and advanced analytics tools.
This project is a testament to how cutting-edge AI technologies can address real-world healthcare challenges. The collaboration with the LlamaIndex team and the adoption of agentic AI frameworks have created a future-proof solution that can evolve with the growing demands of the healthcare industry. As we look forward, this architecture offers exciting opportunities for expanding AI’s role in healthcare, further optimizing patient outcomes and operational efficiency.